금융, 법률 문서 기계독해 데이터
- 분야법률
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-03 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-27 산출물 전체 공개 소개
● 금융, 법률(ODT, HWP, PDF, 등) 포함, 다양한 영역의 복합데이터(텍스트, 테이블)를 대상으로 한 MRC QA학습 데이터 구축 ● 정답경계 추출형, Yes/No 단문형, Table 정답 추출형, 다지선다형 등의 다양한 융형의 학습 데이터 구축 및 기계독해 모델 개발
구축목적
금융, 법률 등 전문분야 문서를 지문으로 활용하여 5가지 유형의 질문-답변 세트를 생성, 인공지능을 훈련하기 위한 데이터셋
-
메타데이터 구조표 데이터 영역 법률 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 한국은행, 금융위원회, 한국금융연구원, 국회입법조사처, 금융감독원, 법제처 라벨링 유형 금융 및 법률 분야 전문문서를 활용하여 기계독해 모델 생성을 위한 지문-질문-답변으로 구성된 40만건의 데이터셋 라벨링 형식 JSON 데이터 활용 서비스 기계독해 기반 질의응답 서비스는 기계독해 기술을 기반으로 한 인공지능이 이용자의 질문을 이해하고 금융 및 법률 관련하여 질문에 대한 답을 찾을 수 있는 서비스 데이터 구축년도/
데이터 구축량2022년/라벨링 데이터 40만건 -
1. 데이터 구축 규모
원시데이터 : 금융 및 법률 분야 전문문서 총 20만 건, 원천데이터 140,226 건, 라벨링 데이터 401,108 건
데이터 구축 규모 데이터 종류 데이터 형태 원문 규모 Q/A 유형 원천 데이터 규모 최종 어노테이션 규모 금융 및 법률 분야 전문문서 html, hwp, pdf 20만 건 정답경계추출형 56,801건 120,318건 Yes/No 단문형 18,203건 40,130건 Table정답추출형 12,000건 120,000건 다지선다형 18,353건 40,404건 절차(방법) 34,869건 80,256건 2. 데이터 분포
- 원천데이터 분야 유형 분포데이터 분포 - 원천데이터 분야 유형 분포 분야 대분류 세분류 구성비 금융 사회과학 경제정책 10.00% 금융 사회과학 금융경제 17.30% 금융 사회과학 금융기관경영 4.20% 금융 사회과학 기업경영윤리 0.90% 금융 사회과학 보험학 2.90% 금융 사회과학 소비경제 2.40% 금융 사회과학 재무관리 0.50% 금융 사회과학 재정공공경제 1.70% 금융 사회과학 회계 0.50% 법률 농수해양학 해사법학 0.60% 법률 복합학 과학기술과법 2.50% 법률 복합학 과학기술법과정책 1.60% 법률 복합학 법여성 0.60% 법률 사회과학 공법 14.10% 법률 사회과학 관광학일반 0.20% 법률 사회과학 기타법학 0.30% 법률 사회과학 노동·법률정책 5.30% 법률 사회과학 무역계약·관습및통상법 0.80% 법률 사회과학 법정책학 0.00% 법률 사회과학 법학일반 10.40% 법률 사회과학 분야별법 17.20% 법률 사회과학 사법 4.60% 법률 사회과학 신문방송학일반 1.40% 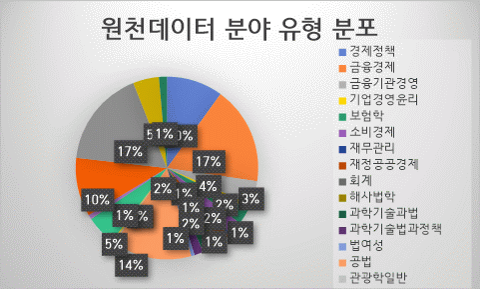
- 원천데이터 출처 분포
데이터 분포 - 원천데이터 출처 분포 분야 세부 출처 건수 구성비 금융 한국은행 27072 19.31% 금융위원회 20389 14.54% 한국금융연구원 외 1016 5.46% 법률 국회입법조사처 72210 51.50% 금융감독원 1412 1.01% 법제처 외 1283 8.19% 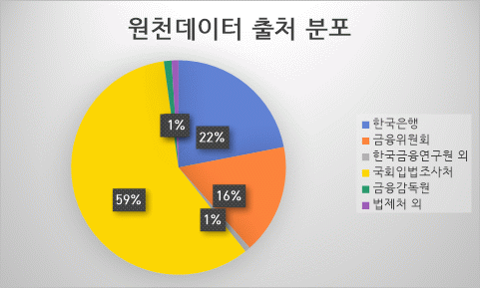
- 질의 문장 어절수 분포
데이터 분포 - 질의 문장 어절수 분포 어절수 구성비 건수 5개 이상~7개 이하 50% 200,000 8개 이상~10개 이하 40% 160,000 11개 이상 10% 40,000 계 100% 400,000 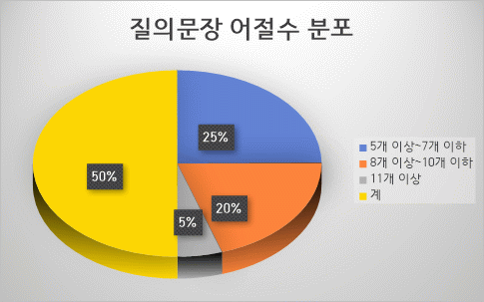
- 답변 어절수 분포
데이터 분포 - 답변 어절수 분포 어절수 구성비 건수 5어절 미만(추출형) 65% 260,000 5어절 ~10어절(절차) 30% 120,000 11어절 이상 5% 20,000 계 100% 400,000 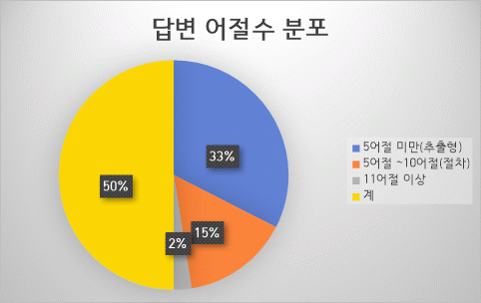
- 표 유형 분포
데이터 분포 - 표 유형 분포 유형 표 형식 구성비 수량 A형 5행 3열(3행 5열 포함) 30% 3,600 B형 5행 4열~6열(4행 5열 포함) 60% 7,200 C형 5행 7열 이상 10% 1,200 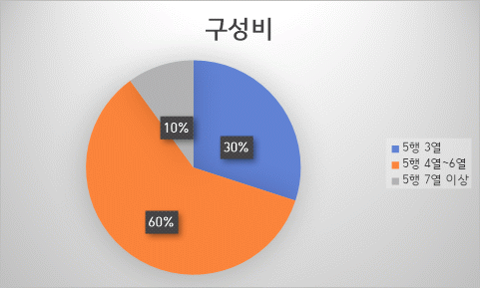
- 의문사 분포
데이터 분포 - 의문사 분포 지문형태 의문사 육하원칙 비율(%) 공통 활용 의문사 정답경계추출형
다지선다형(추론형)
Table정답추출형Who 누구 4% 누가, 누굴, 누군 When 언제 3% Where 어디 5% 어딜 What 무엇 13% 뭐, 무얼, 뭘, 무얼, 뭔 무슨 1% 몇 7% 며칠, 며칟, 어느 8% 얼마 15% 얼만큼, How 어떻게 4% 어떻다, 어떻지, 어떻니, 어떤 10% 어떠한, 어떨, 어때, 어땠, 어떠 Why 왜 0.10% 계 - 70% 절차(방법) How 어떻게 20% Yes/No단문형 Yes/No로 답변 - 10% 100% 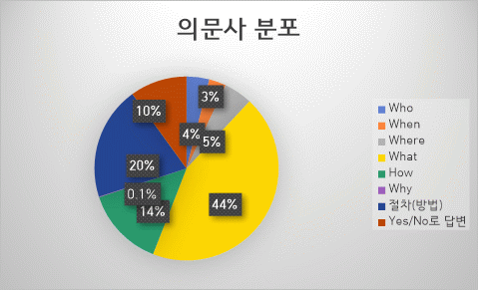
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드ㅇ AI 모델 설계
- 다중 태스크 학습(Multi-Task Learning, MTL): 여러 태스크를 동시에 학습하는 동안 각 작업의 공통점과 차이점을 활용하는 기계학습의 하위 필드
- 기계학습에서의 다중 태스크 학습은 인간이 새로운 것을 학습할 때 기존에 학습했던비슷한 경험을 이용해 보다 빠르게 학습하는 것에 아이디어를 얻음
- 다중 태스크 학습은 학습하는 모든 태스크의 성능을 향상시키는 것을 목표로 한다는점에서, source task와 target task가 구분되어 target task에서의 성능 향상을 목표로 하는 전이학습(transfer learning)과 구분
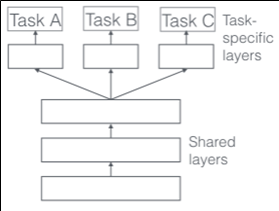
- 딥러닝에서의 다중 태스크 학습은 기본적으로 아래 두 가지 구조를 가짐< hard parameter sharing >
< soft parameter sharing >
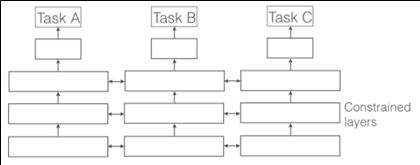
- Hard parameter sharing은 각 태스크의 loss함수에 의해 직접적으로 공유 레이어의parameter가 업데이트 되고, Soft parameter sharing의 경우 constrained layer의 parameter는 서로 비슷하도록 학습이 이루어짐
- 본 연구에서는 아래 그림과 같이 사전학습모델(ELECTRA)의 레이어를 직접 공유하는hard parameter sharing 방식을 사용< 데이터 통합 기계독해 모델 >
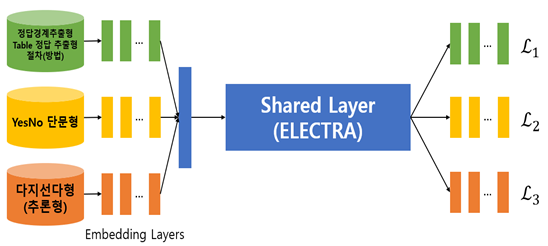
- 각 타입의 데이터는 적절한 인코딩 작업이 이루어지고 난 후 임베딩 레이어를 지나 ELECTRA 모델 입력에 적절한 형태로 변환
- 공유 레이어를 지난 데이터는 각각의 타입에 따라 sub layer로 보내지고, 각 타입에 대한 손실함수가 계산됨<손실함수>
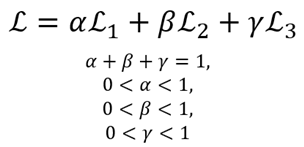
- 최종 손실함수는 각 손실함수의 가중평균으로 계산
ㅇ AI 모델 구현
- HuggingFace에서 제공하는 transformers 라이브러리에 공개된 KoELECTRA 베이스 모델을 기반으로 기계독해 모델 구현
- ELECTRA 모델의 임베딩 레이어는 각 데이터 타입에 따라 분리하여 사용
- 기계독해 태스크에서는 질문, 지문 토큰을 입력으로 받아 지문의 각 토큰이 정답의 시작, 끝 여부를 예측한다.
- 각 토큰의 예측 값 중 가장 높은 값을 최종 정답으로 출력한다. 이 때 정답 영역은 가장 높은 값을 갖는 시작 토큰부터 끝 토큰까지로 한다.
- 표 정보 데이터에는 사전학습 모델이 학습하지 못한 표 영역을 나타내는 토큰이있으므로, 이 토큰을 vocabulary에 추가하여 학습한다.- 추가된 토큰: "< table", "< table >", "< /table >", "< tbody >", "< tbody", "< /tbody >", "< tr >", "< tr“, "< /tr >", "< td >", "< td", "< /td >", "border", "colspan", "rowspan”
< 개별 태스크 기계독해 모델 구조 >
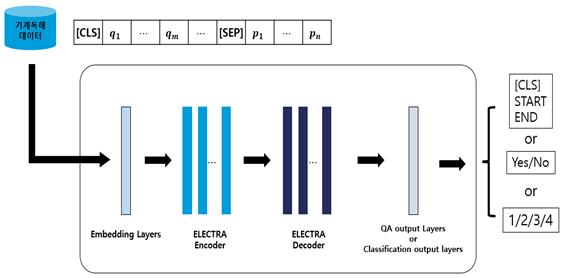
- 개별 태스크는 위 그림과 같은 구조로 구성됨
- [CLS]: (기계독해 태스크에서) 정답 가능성을 나타내는 토큰 (special token)
-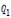 ~
~ 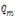 : 질문 토큰
: 질문 토큰
- [SEP]: 질문과 지문을 구분하는 토큰
-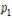 ~
~ 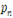 : 지문 토큰
: 지문 토큰 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 기계독해 질의-응답 정확도 Question Answering Multi-task learning on pretrained language model Accuracy 81 % 90.58 % 2 기계독해 질의-응답 정확도 Question Answering Multi-task learning on pretrained language model F1-Score 0.81 점 0.8564 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- JSON2. 데이터 구조
2.1 용어데이터 구조 - 용어 구분 속성명 타입 필수여부 설명 예시 1 Dataset object Y 데이터셋 메타데이터 1-1 Dataset.Identifier string Y 데이터셋 식별자 TEXT_QnA_FinancialLaw_01 1-2 Dataset.name string Y 데이터셋 이름 금융법률 문서 기계독해 데이터 1-3 Dataset.src_path string Y 데이터셋 폴더 위치 /dataSet/text/ 1-4 Dataset.label_path string Y 데이터셋 레이블 폴더 위치 /dataSet/text/ 1-5 Dataset.category number Y 데이터셋 카테고리 2 (2:질의응답) 1-6 Dataset.type number Y 데이터셋 타입 0 (0: 텍스트) 2 data array Y 레코드의 리스트 2-1 data[].doc_id string Y 문서 번호 FL000001 2-2 data[].doc_title string Y 문서 제목 꿈을 키우는 「FSS 대학생 금융교육 봉사단」 제9기 출범! 2-3 data[].doc_source string Y 문서의 발행기관명 법무부 2-4 data[].doc_published number Y 문서의 발행시기
(YYYY 또는YYYYMM 또는 YYYYMMDD)2021 또는
202111 또는
202111102-5 data[].created string Y 데이터셋 생성일시
(YYYYMMDDHH24MISS)202203071313 2-6 data[].doc_class object Y 문서의 분류 정보 2-6-1 data[].doc_class. class string Y 분류 기준 금융/사회과학/금융경제 2-6-2 data[].doc_class.code string Y 분류 기호 보도자료 2-7 data[].paragraphs array Y 지문의 리스트 2-7-1 data[].paragraphs[].context_id string Y 지문 번호 C_000001 2-7-2 data[].paragraphs[].context string Y 지문 2-7-3 data[].paragraphs[].tbs array N 표 레이어 Table형 지문에 포함 2-7-3-1 data[].paragraphs[].tbs[].table_id string N 표 번호 2-7-3-2 data[].paragraphs[].tbs[].table_title string N 표 제목 2-7-3-3 data[].paragraphs[].tbs[].table string N 표 T_000001 2-7-4 data[].paragraphs[].qas array Y 질의응답 쌍의 리스트 2-7-4-1 data[].paragraphs[].qas[].qa_type number Y 데이터셋 유형 1:정답경계 추출형, 2:Yes/No 단문형, 3:Table 정답 추출형, 4:다지선다형(추론형), 5:절차(방법) 2-7-4-2 data[].paragraphs[].qas[].question_id string Y 질문 번호 Q_00000001 2-7-4-3 data[].paragraphs[].qas[].question string Y 질문 2-7-4-4 data[].paragraphs[].qas[].answer object Y 답변 레이어 2-7-4-4-1 data[].paragraphs[].qas[].answer.source string Y 답변 출처 지문/표 번호 2-7-4-4-2 data[].paragraphs[].qas[].answer.text string Y 답변 텍스트 “금융교육” “yes“ “no“ 2-7-4-4-3 data[].paragraphs[].qas[].answer.answer_start number N 답변의 시작 위치 2-7-4-4-4 data[].paragraphs[].qas[].answer.answer_end number N 답변의 끝 위치 2-7-4-4-5 data[].paragraphs[].qas[].answer.cell_text array N 답변 셀 텍스트 [‘한국’,‘미국’,‘중국’] 2-7-4-4-6 data[].paragraphs[].qas[].answer.cell_coordinates array N 답변 셀 위치 [‘(2,1)’,‘(2,2)’,‘(2,3)’] 2-7-4-4-7 data[].paragraphs[].qas[].answer.clue[].clue_text string N 답변 근거 텍스트 2-7-4-4-8 data[].paragraphs[].qas[].answer.clue[].clue_start number N 답변 근거의 시작위치 2-7-4-4-9 data[].paragraphs[].qas[].answer.options array N 다지선다형
보기 답변["금융감독원", "학생", "고령층", "김은경"] 2.1 데이터 예시
- 정답경계 추출형
- Table 정답 추출형

- 다지선다형

- 절차(방법)형

-
데이터셋 구축 담당자
수행기관(주관) : ㈜넥스인테크놀로지
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정회용 02-857-6230 [email protected] 사업총괄관리, 데이터 품질관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 나라지식정보 원시데이터 수집, 정제, 가공 단아코퍼레이션 원시데이터 수집, 정제, 가공 ㈜포티투마루 AI 모델링 ㈜유클리드소프트 저작도구 연세대학교 산학협력단 품질검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정회용 02-857-6230 [email protected]
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 [email protected] 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.